By: Dwayne Parkinson - Solution Architect
 We all like to believe that technology makes everything somehow better, right? Our parents’ watches tell time and maybe the date while mine gives me the weather, tells me when to get up and exercise, tracks calories, integrates with email and sends text messages. Seemingly everything from our refrigerator to our garage door opener to the latest and greatest ERP system is connected to our phones and devices these days. Yet amidst all this technology and integration, lurking somewhere in the bowels of virtually every company and organization is a massive pile of paper.
We all like to believe that technology makes everything somehow better, right? Our parents’ watches tell time and maybe the date while mine gives me the weather, tells me when to get up and exercise, tracks calories, integrates with email and sends text messages. Seemingly everything from our refrigerator to our garage door opener to the latest and greatest ERP system is connected to our phones and devices these days. Yet amidst all this technology and integration, lurking somewhere in the bowels of virtually every company and organization is a massive pile of paper.
They say the first step to fixing a problem is to admit that we have one. So let’s admit what the problem is: paper. It used to be that paper went back and forth between companies as a record of the various transactions. If you placed an order, it was on paper. When you got a shipment, there was more paper. When you needed to pay, there was a paper invoice. And up until recently, when you paid, someone somewhere was potentially issued a paper check. With the advent of the Electronic Data Interchange (EDI), electronic transactions thankfully became the standard - or so we’d like to think. What’s really happened however is that only those transactions between electronically astute organizations have migrated to EDI, while smaller organizations and those facing significant technology challenges have unfortunately remained largely paper-based.
While many of these smaller organizations have stopped sending physical paper for these transactions, it’s important to recognize that an e-mail with a PDF attachment is still a paper-based transaction in the end. Ultimately it requires a person somewhere to open the attachment, read it, extract the important information, and then enter that information into the business system. Due to this process, the end result is that there are very few organizations that are completely free from the shackles of paper.
 The obvious solution is to use some kind of scanning and optical character recognition (OCR) to try to automatically import data into the systems. The problem with this solution is that many existing OCR systems use technology that hasn’t changed in twenty years. Often enough the legacy processes - defining templates, creating scanning zones, forcing customers to use predefined forms and cryptic barcode solutions - all fail for various reasons.
The obvious solution is to use some kind of scanning and optical character recognition (OCR) to try to automatically import data into the systems. The problem with this solution is that many existing OCR systems use technology that hasn’t changed in twenty years. Often enough the legacy processes - defining templates, creating scanning zones, forcing customers to use predefined forms and cryptic barcode solutions - all fail for various reasons.
Oracle Forms Recognition (OFR) approaches the problem of scanning in a very different way. First of all, the software is designed to simulate what a human might do when looking at a piece of paper. The first thing a person does is to evaluate the document and figure out what the document is. Is it a W2? Is it an invoice? Is it a resume? OFR does the same thing. Based on the layout of the document, the actual content, and several other metrics OFR classifies a document automatically.
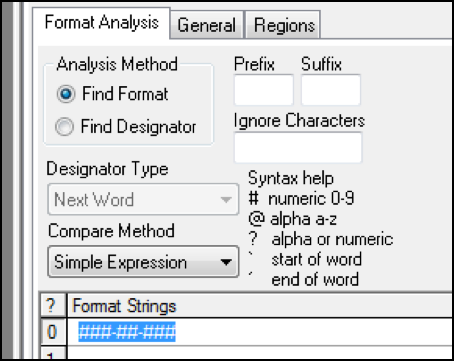
Once classified, rules are set up to define what various pieces of information look like within that document. For example, a Social Security Number is always in the same general format; three digits a dash, two more digits and another dash followed by four digits (999-99-9999). When a person looks for a Social Security Number on a piece of paper they look for a couple of things:
- They also look for a specific format
- They look “geographically” in the general area where they expect the social security number to be based on the document type and past experience
OFR does that exact same thing. Here we are defining a simple rule for a social security number:
Based on that rule OFR will identify candidates on the scanned documents as shown here:
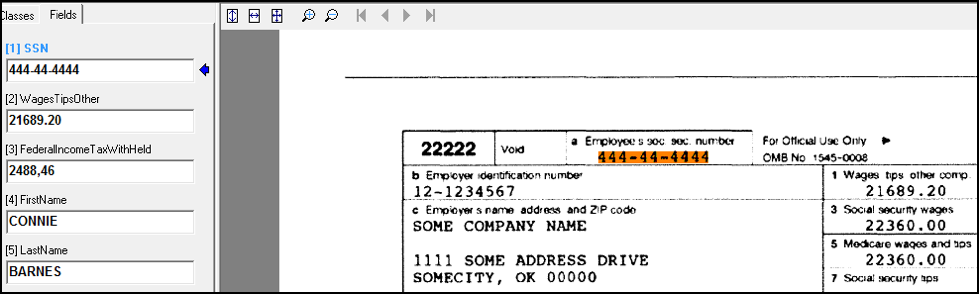
With OFR, rules can be defined to specify formats or to look next to, above or below certain identifiers (i.e “SSN” and “Social Security Number”).
Once the rules are in place, OFR identifies candidate values on the document and OFR is then trained on sample documents so it can learn where to expect to find each value. This process is known as creating a “learn set”. Batches of sample documents are scanned and “taught” to OFR so that when it encounters similar documents in the future it will already know how to handle them.
Here we see the evolution from the traditional scanning/OCR model. With the OFR approach it isn’t necessary to define separate templates for each type of document that might come into the company. Instead a single document class is created to represent a group of information that is needed from a class of documents. For example, there may be one class for information contained on a W2 tax form and another class for health insurance information retrieved from various health provider forms. With just two classes defined, OFR can handle all of the variations of W2 forms and all of the healthcare provider forms a company might reasonably encounter.
In the event that OFR encounters a problem such as a light scan or invalid data, there is an intuitive browser-based verification system that allows users to review the exception data and make an informed decision. OFR can also be configured so that each piece of data it finds is measured against a certainty level. So whenever OFR is unsure if the data it has is correct (that is, the certainty level is low), the item can be sent into the verification system where a person can review it. Additionally, as documents go into the verification system they can be flagged to help further train the system so the accuracy of the system continues to improve over time.
Behind all of this technology is a powerful scripting engine that provides the ability to customize the process as needed and integrate with other systems and a host of other standard OCR technologies. These include optical mark recognition (OMR), barcode recognition, zonal OCR, floating anchors and pre-processing technologies such as box and comb removal.
We’ve seen wild success with our clients through the adoption of modern, powerful and flexible scanning solutions like Oracle Forms Recognition. From relatively simple needs of only several hundred documents a week to much larger operations, OFR and WebCenter Capture can help you evolve your processes and ultimately cage the Paper Tiger.


No Comments Yet
Let us know what you think